
Recovery System

- Transaction의 durability와 같은 내용에 대해서 다룬다.
- Db에 장애가 발생해도 DB 시스템은 안전하게 유지되게 만드는 시스템이다.
- Fail 에서도 데이터 완전 무결성 보장하게 만드는 것이 Recovery system 이다.
when?
- Transaction 자체의 실패( rule 지키지 못함)
- 서로 다른 transaction 수행할 때, deadlock 발생시 시스템이 특정 transaction 중단 가능
- 시스템 자체에 문제 생길 수 도 있다. (누가 전원 끈다거나.. 등)T1 이 A,B 에 write로 수정시, 둘 중 1개만 update같은건 안된다.
Transaction은 겉으로 보기에 묶여있는 듯하지만, 놀리적인 개념이기에 실제로 일부는 DB에 반영되고, 일부는 반영에 실패할 수 있다. 이런 상황 발생하면 안되기에 사전에 방지하거나, 문제가 발생하면 해당 트랜잭션을 rollback해야한다.
Dualbility: 사용자 변경 사항은 무슨 일이 있어도 반영되어야 한다.
Recovery 2가지 고려사항
⦁ Normal 상황에서 복구 데이터 준비 ( 문제 없어도 준비)
⦁ 실제 장애 발생시, 다시 동작 가능하게 만들기.
Volatile: 전원 나가면데이터 유실가능
Non-volatile ( 전원 나가도 정보 유지) : 디스크 망가지면 데이터 유실.
하지만 이거까지 따지면 복잡해진다. 따라서 volatile의 손실만 가정하고 모든 지식들을 해결할 것이다.
- Stable storage: 어떤 상황에서도 안전 상황 보장하는 저장공간
- Physical block: disk에 거주하는 block
Buffer block: main mem 거주하는 block - Input(B): physical block을 main mem으로 transfer
- Output(B) : main mem의 Buffer block을 disk로 transfer, 비워진 main mem에 적절한 block 넣기.
- 메모리에 에 block이 없다면 시 disk에서 불러와야 한다. (input)
- 각 transaction은 private work-area 존재한다.( 접근하는 모든 data item에 대한 local copy + 자신이 update하는 data item 저장)
System buffer block <> private work-area 사이에는?
xi: buffer block안의 data item X 에 대한 트랜잭션의 local 사본.
Read(X): local var xi 에 X 저장
Write(X) : local var xi를 buffer block 안 X에 저장.
만약 X가 memory에 거주 x 시, input(Bx) 먼저 수행 ( disk에서 가져오기)
* output(Bx)는(disk write) 꼭 write(X) 뒤에 바로 따라오지 않아도 된다. (시스템이 적절한 때에 변경된 X를 disk에 완전히 저장하는 output 수행)
Transaction:
데이터 item X에 접근 하기 전에 Read(X) 먼저 수행해야한다
Write(X): transaction이 commit 되기 전 아무 때나 가능!

T1, t2는 각각 local 공간 보유. Transaction 끝나면 local storage 필요x 기에 없앤다.
Atomicity
transaction에서 데이터를 바로바로 버퍼에 저장하면 atomicity 완벽히 보장하지 않는다. 따라서 transaction 종료 전까지 모아 놨다가 종료되면 반영한다.
이때 사용하는 방법이 log.
옛날엔 shadow page라는 기법도 사용했다.
shadow page
원래 대상과 동일 카피 만들고, 변경사항 있다면 copy에 저장하고
모든 변경 사항이 반영된 것을 보이는 방식
->전체에 대해 새로운 걸 만들어야 하는데, 적은 부분만 수정할 경우, 오버헤드 너무 심함
- 동시에 고치는 것도 불가능하다.
- page가 랜덤 access 가능
Log-based recovery
변경된 내용만 기록한다. >> I/O 효율 good
Log: log record의 모음.
Log는 변경사항을 순서대로(sequential)하게 기록해서 랜덤 access가 아닌 seq access 가능.
특정 레코드만 추려서 볼 수 있다.
로그 표현
Ti 트랜잭션 시작시 <Ti, start>
Write(X) <Ti,X,V1,V2> >> X:data item V1: X의 old val, V2: X의 new val
Transaction이 종료시 >> <Ti,commit>
Commit을 했다는 것은, 해당 transaction은 어떤 문제상황에서도 손실 x 보상
>> log에 정보 담김. 사용자가 commit log를 확인했다>> 정보가 온전히 저장되었다는 것을 의미
Transaction committed 의 의미: commit log record 값이 stable storage에 output 완료됨.
database modification: update가 disk or buffer block에 수행됨 (local variable in private area는 x)
transaction의 local > write 로 buffer block에 ) >output으로 buffer block의 데이터를 disk에
immediate Vs deferred
변경사항이 log 통해 기록되었다. >> block들은 disk에 저장될 수 도, 안될 수 도.
Buffer가 transaction에서 변경되는 부분~~
Immediate modification
transaction: write(변경) 작업>> 버퍼에 그때 그때 기록하는 방식
(database modificaion이 transaction commit 전에도 허용)
Update된 log record가 DB modification 전에 write되야.
(log record 의 output을 연기하는 방법도 추후 나온다)
Update 된 buffer block을 output( disk write)하는 건 transaction commit 전,후 전부 가능.
deferred-modificatoiin
변경(write)들을 local storage에 모아 놓고, commit 시점에 한번에.
2번은 모든 update 사항에 대한 copy를 저장하는 오버헤드 많아서 1번 위주로 진도 나간다!

- Immediate에선 commit 전 후 로 output이 가능하다.
- 변경 전에, log로 기록을 남긴다. >> output이 되어도 log기반으로 복구가능
- Log로 저장하든, buffer 전체를 그냥 저장하든, 꼭 저장해서 durability 유지해야한다. (Log가 더 I/O 효율 좋아서 씀)
- Commit 시점에 log가 write 등 변경사항 저장해야 한다.
- Buffer는 한정 되어 있다. => 버퍼 매니저로 인해 메모리에서 밀려나며 output으로 나올 수 있다.
Concurrent transaction
같은 data 대해 서로 다른 transaction이 동시에 기록하는 상황은 존재해선 안된다.
Log는 같은 데이터에 대한 변경사항을 관리하는 것이 하나의 흐름으로 나와야.
>> (동시에 같은 data(item) 수정시 ) 하나의 흐름으로 표현 불가함.
Transacton에 대한 기본 operation.
예시
X 가 a > b >c 로 바뀌졌을 경우
변경사항 취소( 과거 값으로 복구)
Undo: c> b> a 과거 값으로 바꾸는 것. Backward로 가며 그 다음 최신 log record
<Ti,X,V> 형식의 특수한 redo-only record ( X에 기존 값 넣기)
모든 data item을 undo해서 Transaction의 Undo 끝나면 <Ti,abort> 로 버려야한다.
redo:. Forward로 가며 재수행
(rollback 되었지만, 이 부분은 문제 없고, commit log를 통해 disk에 잘 반영된 것을 확인했기에
그대로 다시) => logging 할 필요가 없다.
Undo: commit 전 에러 처리
Redo: commit 후 에러 처리
Transaction abort
Ex) immediate modificatoin일 경우, 그걸 바꿀 필요가 있다.
Undo 가 abort에서 추가 가능.
Recovery operation 에서 마지막 장애가 발생한 상황으로 되돌리고 동작가능한 상태로 만들 때
(Ti가 문제 transaction이라고 가정) backward 탐색.
Transaction Ti에 대한 log를 찾는다
=>start를 찾았는데, Ti 의 종료 ( commit이나 abort)
없으면 Ti가 온전히 종료되지 못한 것 >> undone 해야 ( 변경사항 되돌리고 다시 줄서기)
만약 start 있는데 commit, abort 있다면 redone. ( 다시하면 될 수 있다, 다시해보기)
만약 Ti가 undone 된 뒤, <Ti,abort>가 log에 적히면?
Ti undone 수행.>> 변경값을 new value로.
>redo-only record를 통해 다시 update 된 value를 old로.
이런 repeat history 방식이 별로 같지만, recovery 과정을 simplify해서 나름 좋다.

⦁ : T0 종료 x
⦁ T0 종료, T1 종료 x
⦁ T0,T1 종료
각 상황에서 해당 영역에서 recovery해야할 때.
⦁ : log가 T0의 종료 확인 못함. T0를 강제로 중단 시킨다( abort)
>> A를 1000> 950으로 write , B를 2000> 2050 으로 바꾸는 연산이 log에 있는데,
이 두 연산을 undo 해야한다. ( 다시 A 를 1000으로, B를 2000으로)
>> T0가 abort된 안전한 상태로 log 완전히 기록한다.
To undo
⦁ To는 종료 온전히 => redo
T1 > undo
T1은 종료 x abort 해서 원래 상태로. T1은 C 700> 600 바꿧기에 다시 600으로 변경
( c ) 모든 사항들이 완전 종료 >> log에 있기에 disk에 온전히 저장된 걸 알 수 있다 good
T0,T1 redo 한다.
check point
( stable storage 지점 표시), L은 active한 transaction을 모아둔 list이다.
체크 포인트를 통해 마킹. 체크 포인트 2~ 3 에서 문제 발생시 2~ 3 트랜잭션만 recovery 작업.
Log를 보며 수정된 block을 disk에 output한다 >> 안전한 세이브 된 것.
>> disk에 output 된 것까지가 checkpoint
업데이트한 데이터가 실제 abort 되는가?
Check point에는 active한 transaction과 non-active transaction 구분해야.
(active한 transaction 수정하면 안됨…. 수정중인 정보에 접근할 수 있기에)
⦁ 최근에 main memory에 거주한 모든 log record들을 stable한 storage에 output한다.
⦁ 모든 수정된 buffer block을 disk에 output 한다.
⦁ 이란 로그를 stable storage에 write한다( L은 checkpoint시점에 active한 모든 transaction 을 모아둔 list)
요약: main memory의 log, 수정된 buffer block을 모두 output하고 check point 찍기.
>>checkpointing하는 중에는 모든 updates가 멈출 수 있는 문제( 누군가 disk에 기록중인 정보를 수정 시, 접근 x >> active transaction의 데이터 수정한 경우)
Active List가 있어야함!! 또한 이방식은 로그도 기록, dirty 버퍼 도 기록 ,. ….. 너무 좋지 않다
( 뒤에 better 방식 설명)

Check point 시점에 active transaction 있어서 fail하면, 그 지점만 recovery하면 된다.
Failure 직전에 active transaction 목록 저장하고, 해당 리스트 안 모든 trasaction을 abort 한 뒤 recovery 진행.
실제 동작가능한 recovery 알고리즘 대해 ( 앞은 실 사용하기엔 별로다)
트랜잭션 시작시 >> < T,start>
매 update 마다 >> <Ti,Xi,V1,V2>
종료 시 >> <Ti, commit>
Transaction rollback 하는 법
Log를 가장 최근부터 backward로 scan하며
<Ti,Xj,V1,V2> 이런 write log 를 찾는다.
그리고
<Ti,Xj,V> ( special redo-only log record) 로 write해서 변경한 정보를 원래의 old value로 rollback.
( write를 상쇄시킨다.)
<Ti,start> 나올때까지 rollback 진행한 뒤, start 찾으면 <Ti,abort> 를 log에 write해서 해당 transaction을 버리는 것이 완료된 것을 알린다.
* < Ti,Xj,V1,V2> 는 단순 기록. 실제 write 아니다!!
실제 recovery algorithm: 2 phase
( 마지막 체크포인트부터 forward방향으로 redo phase에서 redo하면서 undo-list 만든다
앞서 만든 undo-list 기반으로 backward 방향으로 undo phase 실행)
Redo, undo 절차
<1> Redo phase
⦁ 마지막 찾기, L에 undo-list set하기 (찾은 check point 부터 redo시작)
(기존에는 L에 active list 있었다)
⦁ Redo를 위해찾은 부터 forward scan하며 undo-list에 값 추가하기
( redo는 log 남길 필요 x)
2-1) <T,X,V> <T,X,V1,V2> 등 연산 발견 시, X에 V2 or V를 쓰는 것으로 redo 한다.
2-2) : 새로운 트랜잭션 확인 시 undo-list에 추가. ( 해당 transaction은 undo되야한다)
2-3) 레코드 중 commit or abort로 완료된 Transaction 있으면 undo-list에서 제거
<2> Undo phase:
backword 진행, undo-list의 트랜잭션들을 rollback 한다
⦁ Undo list 안 Ti에 대한 <Ti,Xj,V1,V2> (write)가 찾아지면
Xj 에 Vi를 write하여 undo 실행한뒤, <Ti,Xj,V1> 이라는 보상 로그 작성
⦁ Undo-list 안의 Ti 에 대한 <Ti,start> 가 찾아지면
<Ti,abort> 로그를 작성한 뒤, Ti를 undo-list에서 제거 (undo 완료!)
⦁ Undo-list가 빌 때까지 진행
Undo 종료후 다시 시작 가능.
** read, write 로 buffer block 수정 >> 수정된 buffer block 은 disk에 기록되야!
Log >> read, write를 나타내는 log record.
아래 로그가 recovery 수행시, 2phase의 방식. 맨 아래 2줄은 undo phase에서 추가된 log

마지막 체크 포인트부터 시작. (T0는 개별로 abort 됨)
<T1,C,700,600> redo ( C에 다시 600을 write)
감지 > undo-list에 추가.
<T2,A,500,400> >> redo ( A에 400을 다시 write)
< T0,B,2000> >> rollback 작업
<T0,abort> >> T0 rollback 완료
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
Undo phase: undo-list에 T2 존재. 거꾸로!
<T2,A,500,400> >> (아까 redo로 다시 400됬었다)
A에 다시 500을 write 후 <T2,A,500> 작성.
<T2,start> >> T2 종료 확인! <T2,abort> 로그 작성 후 Undo-list에서 제거
=> undo-list 텅 비었기에 종료!
(redo 는 log x undo 만...)
데이터가 변경될 때마다 매번 disk 접근은 효율 bad>> buffer를 사용한다.
Log도 버퍼 사용 가능.
Log가 각 변경사항의 durability 보장하기 위해 매번 disk에 I/O 하는 건 bad.
Log record도 buffer에 모았다가 disk에 기록.
하지만 commit 시점에서는 버퍼가 모두 disk에 기록되어야 한다!
Buffer full> log force
Log record들은 stable storage에 record들의 생성 순서로 output 되어야한다.
(data block(database buffer)는 순서 상관 없이 output 가능)
<Ti,commit> log가 stable storage에 output 되어야만 Ti 트랜잭션은 commit state에 들어온 것.
버퍼 매니저는 한정된 메모리에서 disk 데이터를 메모리에 올려서 사용.
페이지가 교체될 수 있다! >> recovery가 복잡해짐
(중요!!!). write – ahead logging or WAL : main memory의 데이터 block 이 db에 output되기 전에, 그와 관계된 모든 log record이 먼저 stable storage에 output 되야한다.
저장 장치 내에는 각 변경사항에 대한 모든 히스토리가 있어야 하는데, 마지막 페이지 단 1개만 mem에서 내려왔으면>> 마지막 상태만 기록 되어있는 이상한 상황.
변경 후 에 대한 데이터만 있고, 그 사이의 log가 없으면 복구를 제대로 할 수 없다.
따라서 page가 버퍼 매니저에 의해 disk로 output( disk write) 되면, 그 전 까지의 log 들도 자동으로 output( disk write) 되어야한다.
Steal & Force
트랜잭션이 완료된 후(commit 직후) 바로 데이터를 디스크에 기록할 것인가?
⦁ Force: 바로 기록한다
⦁ No-Force: 바로 기록하지 않는다(Redo 필요) >> 복구를 위해log만 저장 해놓자!
트랜잭션이 완료되지 않은 상태(commit 전)에서 데이터를 디스크에 기록할 것인가?
⦁ Steal: 기록한다(Undo 필요)
(단, 해당 update 대한 로그가 먼저 output>>ahead logging)
⦁ No-Steal: 기록하지 않는다
선호: no-force, steal policy
>> 따라서 redo, undo가 필수다!
Steal
수정된 페이지가 commit 전에도 disk에 output 될 수 있기에 UNDO 로깅과 복구가 필요 (아직 commit되지 않은 정보가 block에 들어 있을 수 있기에)
>>disk에 update한 block을 output 할 때, 꼭 관련된 log도 같이 해야! == ahead logging
No-force
commit한 트랜잭션의 내용이 디스크 상의 데이터베이스 상에 반영되어 있지 않을 수 있기 때문에 반드시 REDO 복구가 필요하게 된다( commit 되었음에도, 바로 output x 기에.)
=>log는 disk에 꼭 올려놔야한다!
Block이 disk에 output 될 때는, 그 안에서 아무런 update도 진행되선 안된다.
>> data item을 Write 하기 전에 transaction 해당 item 보유한 block에 X-lock을 건다.
Write가 완료된 뒤 X-lock 해제. ( 짧은 시간 동안만 lock 된다 >> 이런걸 latches라함)
X-lock= exclusive lock( write lock으로 쓰임)
Disk에 block을 output 하는 과정
⦁ Exclusive latch를 block 에 걸어 update 방지
⦁ Log flush 수행
⦁ Black 을 disk에 output
⦁ Realease latch
Fuzzy checkpointing
Check point 과정: log, diry buffer를 전부다 disk에 기록하는 과정에서 X lock을 사용해서 update가 모두 먹히게 되는 문제 발생.
=> transaction 수행 크게 제한.
X lock은 페이지 내용을 고치는거에 막히는게 아닌, I/O에 막히게 되어 오래 기다리게 된다.
>> 모든 transaction 처리가 막히는 문제 발생.
>checkpoint 중간에 업데이트가 안되는 것이 근본적인 원인.
따라서 checkpoint 중간에도 update 되게 한다.
( 기존엔 checkpoint 끝나야 사용 가능
>> checkpoint 먼저 다 하고 output??
Dirty buffer: 아직 수정사항이 output 되지 않은 buffer block
Checkpoint recall 과정 ( 기존)
⦁ 모든 log record output
⦁ 모든 수정된 buffer block output
⦁ 최근 checkpoint의 log record Write
>> 너무 오래 interrupt( 대기) 발생.
만약 checkpointing 중 update 허용 시 >> ( 불완전한 방식)
⦁ 모든 log record output
⦁ 레코드 write & output ( 체크 포인트 빨리 업데이트하기)
⦁ 수정된 buffer block들 output
>> checkpoint를 불완전하게 한다.( buffer block output하기 전에
update하다가 fail 발생하면 fail한거는 dirty buffer로, check point 안에 들어오면 안된다..)
이 상황에선 check point 찍혔지만, 아직 디스크에 저장되지 않은 dirty buffer가 존재할 수 있고,
여전히 반영될 로그가 있다는 의미. >> 단순히 순서만 바꿔서는 복원작업 진행 불가.
>> Fuzzy checkpoint.
Fuzzy checkpoint
앞에선 checkpoint를 만들 때 실행 중인 모든 트랜잭션을 중지하고 디스크에 버퍼의 값을 저장하게 된다. (active list 의 transaction abort하고 했음)
트랜잭션을 중지하지 않고(아주 잠깐 정지) checkpoint를 만드는 방법이 Fuzzy checkpointing이다.
Dirty buffer를 모두 flush x check point에서 모든 dirty buffer list>> 언젠가 모두 flush 되는 시점에 해당 checkpoint, 시점에 업데이트. ( 정확한 마지막 체크 포인트?
Dirty buffer(수정되었지만 아직 output x 인거) 존재 시 불완전> 이 시점 recovery하면 안된다..
마지막에 온전하게 checkpoint 된 시점 ( =모든 dirty buffer가 flush된시점)을 체크
Flush: output 완료.
Fuzzy checkpoint
리커버리 시 체크포인트 이후만 관리할 수 있도록 보장하기 위한 기법
checkpoint 호출 시 처리 방법
⦁ 일시적으로 모든 트랜잭션의 update를 중단시킴
⦁ 로그 레코드를 남기고 force log 를 수행 (로그 블럭을 stable stoarge 에 저장, WAL)
⦁ 변경된 데이터 블록(dirty)을 리스트화 시킴 (리스트 M)
⦁ 일시적으로 멈춰두었던 트랜잭션의 액션들을 재개
⦁ 리스트 M의 모든 블럭을 디스크에 저장함
이로서 checkpoint 이전의 모든 행위들은 디스크에 저장된 것이므로 이후의 과정에 대해서만 리커버리할 수 있음
리커버리 알고리즘이 fuzzy checkpoint 기법을 사용한다면 stable storage 에서 last_checkpoint 를 관리함
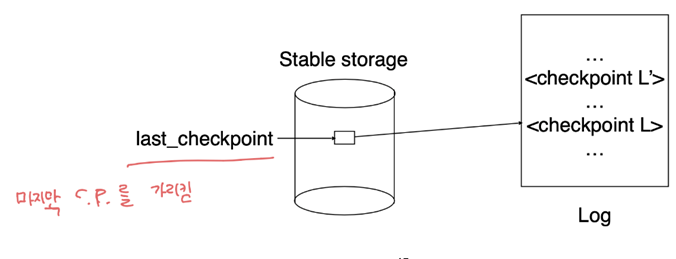
즉 리커버리가 될 때 로그를 순회하면서 마지막 체크포인트를 찾아다니는 것이 아닌 last_checkpoint 로 찾아가 바로 forward scanning 수행
'데이터베이스(rebooting now)' 카테고리의 다른 글
| [db] concurrency (0) | 2022.12.27 |
|---|---|
| [db] transaction (1) | 2022.12.27 |
| [db] query optimization (1) | 2022.12.27 |
| [db] query processing (1) | 2022.12.26 |
| [db] indexing part-2 (B+ Tree) (0) | 2022.12.26 |