
indexing이란?
인덱스를 설정하면 해당 컬럼들의 값을 해시 맵 형태로 메모리에 저장해두고 검색할 때 메모리에서 검색을 먼저 하고 해당하는 행을 찾아 반환하지만 인덱스 생성하는데에도 비용이 들고, 데이터 수정, 추가 시마다 업데이트가 필요하기에 데이터의 추가, 수정 삭제에 대한 처리 속도가 낮아진다.
그렇기에 인덱싱으로 "유의미한" 검색 성능 향상을 만들 수 없다면, 만들지 않는 것이 좋다.
그럼 언제 인덱싱이 효과적이지 못할까?
인덱싱이 효과적이지 않은 상황
- 작은 테이블: 작은 크기의 테이블에서는 인덱스가 적용되어도 큰 차이를 만들지 못할 수 있다. 이런 경우에는 인덱스를 적용하는 대신에 테이블을 자주 스캔하는 것이 더 효율적일 수 있다.
- 자주 변경되는 테이블: 자주 데이터를 추가, 수정, 삭제하는 테이블의 경우 인덱스 업데이트 비용이 많이 들 수 있다. 이러한 경우에는 인덱스를 사용하는 것보다는 검색 대상이 되는 열을 더 작은 테이블로 분리하는 것이 좋을 수 있다.
- 중복된 값이 많은 열( Cardinaliy가 낮은 Column): 인덱스는 중복된 값을 찾아서 검색하는 데 효과적이다. 하지만 특정 열에 중복된 값이 많을 경우, 인덱스를 사용해도 검색 속도가 크게 향상되지 않을 수 있다
ex) 100개의 과일이 있는데, A 상점은 100가지 과일이 있고, B 상점은 10가지 과일이 있다면, A상점은 각 분류마다 1개, B 상점은 10개가 있다. 따라서 "가짓수가 많은" 즉 Cardinality가 높은 A 상점이 원하는 종류의 과일을 찾을 때 더 빨리 찾을 수 있을 것이다.
- 자주 사용되지 않는 검색 조건: 자주 사용되지 않는 검색 조건은 인덱스를 생성하기에 비용이 너무 크기 때문에 인덱스를 생성하는 것이 비효율적일 수 있다.
- 질의 속도보다 데이터 입력 속도가 중요한 경우: 인덱스를 생성하면 질의 속도는 향상되지만, 데이터 입력 속도는 느려질 수 있다. 이러한 경우에는 데이터 입력 속도를 우선시하는 것이 좋을 수 있다.
- 메모리 용량 부족: 인덱스는 메모리를 많이 사용한다(해당 테이블의 해쉬맵을 메모리에 올려서 사용하는 것이기에). 메모리 용량이 한정적인 경우에는 인덱스 생성을 제한해야 할 수도 있다.
매핑 테이블에서 양쪽의 FK를 가지고 인덱싱을 걸어주면 좋다.
why?
매핑 테이블은 대개 매우 간단한 스키마를 가지므로 인덱스를 설정하는 것이 부하에 큰 영향을 미치지 않다.
하지만 매핑 테이블은 보통 그 크기가 꽤 크기에, 인덱싱을 사용하면 적은 부하로 큰 효과를 얻을 수 있다.
하지만, mariadb외 다양한 rdbms들은 자동으로 PK, UK, FK 등에 index를 걸어주기에 별도로 설정할 필요는 없다.
+WHERE 절에 사용되는 컬럼에 인덱스를 생성하는 것이 특히 효율이 좋다.
이제 위의 내용을 고려하여, 실제 엔티티 테이블과 명세를 보고, 인덱싱을 사용하면 좋을지, 그리고 인덱싱을 한다면 어느 컬럼에 하면 좋을지 생각해보자.
인덱싱 수행
아래는 friend 라는 친구관계에 대한 엔티티이다.
@Entity
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Getter
public class Friend {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "from_member")
@JsonIgnore
private ClubMember fromMember;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "to_member")
@JsonIgnore
private ClubMember toMember;
@Enumerated(EnumType.STRING)
private FriendStatus status;
public void changeStatus(FriendStatus status){
this.status=status;
}
// getters and setters
}
아래는 친구관계를 나타내는 FriendStatus Enum이다.
public enum FriendStatus {
REQUEST,FRIEND,DENY
}
fromMember 는 팔로우 요청을 한 사람, toMember 는 팔로우 요청을 받은 사람이다.
또한 Status를 통해 둘이 맞팔로우인지, 단일 팔로우인지 구분되어지는데, 서로의 팔로우 상태에 따라 Status 컬럼이 변하며 관계를 표현한다.
해당 테이블이 아래와 같은 두개의 쿼리를 주력으로 사용한다고 가정하자.
- member id가 주어질 때, 이 id가 from_member 나 to_member 의 id 중 하나라도 일치하고, Status가 FRIEND인 튜플을 위의 Friend 엔티티에서 찾는 쿼리
- member id가 주어질 때, 이 id가 from_member 나 to_member 의 id 중 하나라도 일치하고, Status가 REQUEST인 튜플 을 찾는
여기서 인덱싱을 하는 것이 효율적일까? 그리고 인덱싱을 한다면 어디에 해주는 것이 좋을까?
인덱싱 전략
실제 구현에서는 차이가 날 수 있지만, 이론적인 관점에서는 사용하는 것이 좋고, from_member와 to_member에 적용하는 것이 좋아보인다.
1) friend 테이블은 크기가 매우 크다: 모든 유저들의 친구관계를 한 곳에 저장하기에, 테이블이 매우 크고, 인덱싱의 효율이 좋을 것이다.( 범위를 좁히는 폭이 유의미하기에)
2) 위와 같은 주요한 2개의 쿼리가 모두 from_member, to_member, status 3개의 컴럼을 가지고 select한다. 따라서 인덱스는 이 3개 안에서 구성하면 search에 유의미한 변화가 발생할 것이다.
3) Status는 Enum 값으로, cardinality(종류)가 낮다. 따라서 중복 값이 많을 것이고, status로 인덱싱을 해도 큰 차이를 유발하기 어려울 뿐더러, 친구 관계는 수정 가능성이 높으므로 Status는 자주 수정될 것이다. 근데 테이블에 수정 사항이 생기면, 인덱스에도 이를 반영해야하기에, 상대적으로 성능향상은 낮으면서, 인덱스의 단점인 "수정 시의 오버헤드" 가 비약적으로 늘어나기에, Status는 인덱싱하지 않는다.
4) from_member, to_member는 쿼리의 검색 조건에도 있으면서도 cardinality( 중복값, 혹은 가짓 수) 가 높고, 수정되는 일이 적다.
따라서 나는 from_member, to_member 두개의 Column을 가지고 인덱싱하는 것이 최선이라고 생각한다.
( 해당 명세의 경우, 만약 상대가 follow를 받아주지 않으면 해당 튜플이 삭제되는 문제점이 있지만, 이는 인덱싱이 주는 이점에 비해 적을 것으로 예상하여 추가하는 것이 좋다고 판단했다.)
아래는 from_member, to_member 을 가지고 인덱싱한 코드이다.
@Table(
indexes = {
@Index(name = "friend_index", columnList = "from_member, to_member") //status 도..?
}
)
@Entity
public class Friend {
.........
private ClubMember fromMember;
........
private ClubMember toMember;
.........
private FriendStatus status;
}
쿼리 프로파일링 기반 성능 테스트
Maria DB의 쿼리 프로파일링 기능을 통해 인덱스의 유무에 따른 성능 분석을 진행했다.
mysql > SHOW VARIABLES LIKE 'profiling';
+-----------------+---------+
| Variable_name | Value |
+-----------------+---------+
| profilling | OFF |
+-----------------+---------+
mysql > SET PROFILING=1; //profiling 활성화
mysql > SHOW VARIABLES LIKE 'profiling';
+-----------------+---------+
| Variable_name | Value |
+-----------------+---------+
| profilling | ON |
+-----------------+---------+
이제 특정쿼리를 실행하고 아래의 쿼리문 실행시 쿼리의 속도를 확인 가능하다.
SHOW PROFILES;
결과
index 를 구성하지 않고 수행할 때의 결과

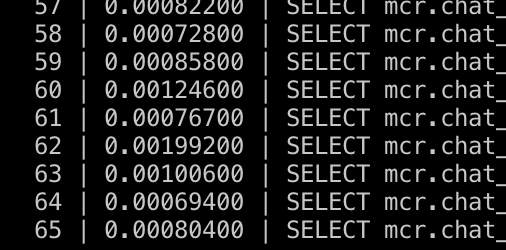
index를 사용하여 수행 시의 결과

결론
인덱스가 없을 때는 약 0.1x초 걸리던 쿼리문이, 0.00xx초 가량으로 크게 감소하였다.
적절한 인덱스를 구성하는 것으로, 눈에 띄게 성능적 차이를 발견할 수 있었다.
trouble shooting
인덱스를 구성할 때, 한가지 주의할 사항이 있다. mariadb에선( 대부분의 RDBMS도 마찬가지) 아래와 같이와 같이 uk 를 형성하기만 해도, 자동으로 index에 등록된다는 점이다. (PK,FK 도 마찬가지)
@Table(
uniqueConstraints={
@UniqueConstraint(
name = "member_chat_uk",
columnNames={"clubMember_id","chatRoom_id"} //각채팅방에는 1명의 유저만 존재한다.
)
}
)
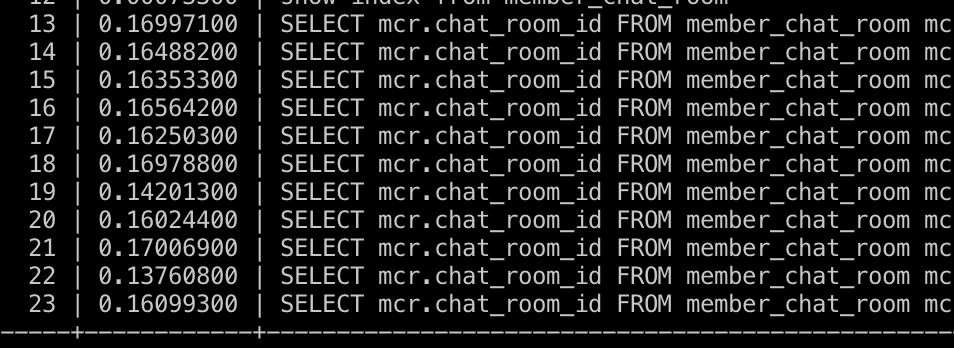
위와 같이 uk를 설정하니, 자동으로 해당 uk에 대해 mariaDB가 아래와 같이 인덱스를 구성한 것을 볼 수 있다.

이걸 모르고 초반에 직접 설정한 인덱스의 유무로 성능을 비교했지만, 의미 없었다. 왜냐면 이미 mariaDB가 자동으로 인덱스를 구성해 주었기 때문이다. 앞서 분석한 쿼리 프로파일링으로 찾아낸 성능 차이는, 이를 인지하고 나서 DDL을 통해 index를 제거한 뒤 비교한 성능이기에, 눈에 띄는 성능 차이를 찾아낼 수 있었던 것이다.
+@
https://codenme.tistory.com/157
[Optimization] 캐싱(caching)을 통한 성능 개선 분석
https://codenme.tistory.com/83 [Optimization] 인덱싱(indexing)을 통한 성능 개선 분석 백엔드 개발자로써, 최적화를 수행하기 위해 수행할 수 있는 것들이 몇가지 있다. 캐시 사용하기 반복적으로 실행되는
codenme.tistory.com
위의 글에서 캐싱으로 인한 성능 분석 역시 진행했으니 관심이 있다면 함께 확인해보자.
'back-end study' 카테고리의 다른 글
| [Optimization] 캐싱(caching)을 통한 성능 개선 분석 (0) | 2023.08.03 |
|---|---|
| 성능 지표에 관하여 (ThroughPut, Latency) (0) | 2023.06.21 |
| HTTP 클라이언트- Apache HttpClient VS OkHttpClient VS Spring WebClient (0) | 2023.06.15 |
| WebClient 이론 및 사용법 (0) | 2023.06.08 |
| Blocking / Non-blocking 과 Sync / Async 의 차이 (0) | 2023.06.08 |