
DeadLock
Deadlock 여부 확인시
- Mutual exclusion
- Hold wait
- Cycle
Non preemption
알고리즘들 ( 그래프 체크> cycle ) 에 더불어 위 상황도 고려해야한다.
Ex) allocation==0 인 놈은 hold&wait 만족 ( hold x 이므로) 따라서 알고리즘 안돌려도 fin=t로 가능하다.
Deadlock avoid
deadllock 이 발생하기 전에 회피하는 대처법이다.
단점: 최악의 경우 가정한다. 자원 활용 떨어짐
Single : claim edge 고려해서 사이클 존재 유무 체크 -> resource allocation graph
만약 사이클 존재시 ‘deadlock’
Multi inst: banker ( safe state) : need<= work(available) 하나라도 fin==false시 Deadlock 가능성이 존재한다.
Deadlock detect
Deadlock 가능성 있어도 ‘현재’ deadlock x 시 진행한다.
단점: detect algo가 자원당 O(n^2)으로 그냥 성능이 나쁘다. ( n개 resource> n^3)
Single >> resource 정보를 지운 wair-for graph에 사이클 있는가?
존재시 ‘현재’ 상태에서 deadlock 존재 의미 (resouce포함 그래프 사이클은 ‘가능성’)
Deadlock 발생하여 발견시 그것을 감지하여 solve한다
banker에서 need<=work >>>request<=work
‘요구를 들어주면 언젠간 자기가 끝내고 받은 자원 돌려주겠지’
( 한방에 끝내는 것만 끝내는게 아니라, 가지고 있는 것 이상을 요구하는 것만 아니면 끝내지 못해도 할당) >> 하지만 work(avail)+= allocation 즉 할당했던 자원은 그대로 수거한다. ( 끝났다고 치는 거)
-> 하나라도 fin ==false 시 deadlock 발생한 것
Solution
1) 버릴 것 찾기 deadlock 없애기 위해 임의로 정해서 process를 버림으로써 deadlock 해소
2) Roll back: 과거 safe state였던 지점으로 복구, restart(deadlock은 결국 확률, cpu sched 등등따라 다른 결과)
‘resource preemption’ Roll back 문제점: starvation -> 일정 횟수 이상 roll back된건 제외시키기
Memoray management
Binding: 실제 주소를 부여하는 것
Compile time bind : 아직 메모리에 올라오지 않음.
Single: pc+1로 예상 가능하다.
multi에선 불가능, 절대 주소 위치변경 불가. ( 물리=logic 주소 )
load time bind: 메모리에 load 할 때 주소 결정. 상대주소. 메모리 어디에 위치할지 모르기에 컴파일러는 ‘relocatable’ 즉 어디에나 올 수 있는 코드 짜야한다. ( 물리= logic 주소. multi 에서 불가능 )
Execution time binding: 프로세스 실행 될 때 주소 변경. (runtime중) 실행 도중 주소 변경 가능.
물리주소 != 논리주소. MMU 통해서 논리 주소 > 물리 주소로 바꿔줌.
transfer time
디스크와 메모리 간 이동시간
Swap in: mem< disk
Swap out: mem> disk
만약 loead, compile time bind>> 원래 위치로 swap in 됨
Execution time>> 아무데나 swap in 가능
User program: logic address만 볼 수 있다. Cpu는 logic add 로만 work
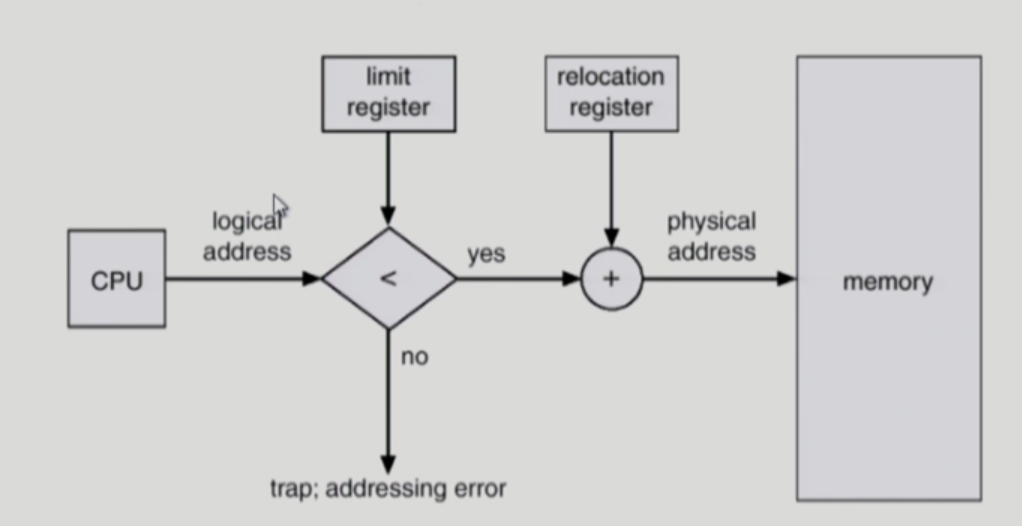
Contiguous: 논리주소 + (MMU의 relocation regi값) = physical add ( swap등 순서변동x 가정)
Base: 접근가능한 최소 물리주소 / limit: 주소의 범위( 크기)
논리주소 < limit 만족 x 시 에러. ( offset < limit)
Contiguous 문제: hole. External fragment >> 연속성으로 유지하려다 발생. compaction으로 해결
Internal frag: 불가피함
Paging: non contiguous
장점: external frag x, . Shared page. Swap out 이 간단하다. 할당과 해제가 빠르다.
단점: 적지만 여전히 internal frag. Ptable 위한 추가 메모리 공간 필요하다.
메모리 접근 2회( ptable이 mem에 위치 >> ptable 1번, 실제 주소 접근 1번 )
-> TLB(look aside buffer) 써서 해결 (locality로 인해 good)
페이지 번호가 tlb에 존재시 mem 접근 없이 base add get!
hit: mem접근 1회 miss: 2회 (원래대로 pagetable 통해 base get)
tlb 를 전부 search 해야 하지만 parallel search(동시에 다읽기) 가능해서 상관x
물리 주소 -> frame
논리 주소 -> page (둘다 block 단위) -> ( offset = 논리주소)
실제 메모리는 frame으로 나눠 놓고, VM 은 page로 나눠짐
Page 를 비어있는 frame 찾아 할당하는 방식.
Ptable로 frame 위치 찾고, 거기서 필요한 것을 offset으로 가져와야한다. ( page내부는 연속적)
Ptable: ptbr( page base regi) , ptlr (page limit regi) ,protection bit
그러나 page는 완전한 연속성 x 따라서 ptlr 외에 valid, invalid bit 사용( pg 빈공간만 invalid )
논리 -> 물리 주소 변환 : page table < mem 상에 위치, random access로, search x)
External frag x , internal frag는 맨 마지막 page 에서만 발생 good!
pg들어오면 무작위로 빈 frame에 넣어놓고, page table에 page의 base address기록.
Shared page: code 영역 공유( self reference 코드: logical 주소 같아야 가능), data는 각자
code영역은 같은 page table 상의 위치, 코드 영역은 다른 위치
1kb= 2^10 (1024)
32bit add, pg size: 4kb >> 4kb= 2^12=12bit 32-12=20 >> 20bit =2^20개 page 위치 저장가능.
1 lev >> 20/12
2 lev>> 10/10/12
Lev 상승 > mem 접근 횟수 증가 >> TLB로 상쇄
Hash: virtual page number >> 성공시 바로 물리 frame get (level 계층구조 너무 높을 때 사용)
문제점: 서로다른 2개가 같은 곳 가르키는 collision
Inverted page table: (기존: page table은 page 마다 1개 항목) >> frame 마다 한 개 항목
Pid / logical address 포함 ( pg num >> pid)
Cpu >>> mem ( cpu에서 나온 process pid 가지고 mem 상의 물리 주소 get)
장점: 공간 효율 good
단점 : 메모리 공간 부족해져서 disk 접근 시간 증가, Table을 전부 찾아야함 >> hash table로 1방에
Page sharing 불가 !!!
Segment : ‘의미 단위’ 로 자르기.
‘서로다른 크기’ 가능해진다. >> external frag 생성, internal frag 는 사라짐.
Segtable: base, limit,protection bit
Protect bit : r/w/x bit 로 접근제어 가능
장점:
-의미단위 묶음
Pg: page 단위로만 묶고 share 가능
Seg: 의미 단위로 묶인 seg 에서 공유 가능.
Ex) 프로세서 p1,p2가 같은 코드 사용> 같은 seg로 묶일 수 있다.
-protection
r/w/x bit 통한 접근 제어
단점: external seg>> internal은 작다, 이게 큰 손실.
해결: segment를 paging 한다.
>>protection bit 사용 가능, seg 단위 share 가능, 거기에 dynamic alloc 안해도되서 ex-frag 없음.
Seg_offset / pg_offset / offset >> s, p, d
s/p 조합으로 TLB 확인 > 존재시 parelel search로 바로 프레임 번호(
physical base) get
2)세그먼트의 base에서 위치에서 s만큼 내려와서 seg 얻음( ptable의 base 포함함)
3)해당 ptable 로 가서 p만큼 내려와서 frame 번호 획득
4)frame번호+d로 물리주소 get
VM
Mem 공간은 부족하다. 그래서 존재하는 개념이 VM이다.
VM: demand page를 메모리에 올려놓은 척하고, 해당 page 사용하려고 하면 재빨리 실제로 올려놓는다.
(disk -> memory swap in)
Page 교체 알고리즘으로 mem 접근 최소화 (mem에 올려 놓으면 빠르다: locality)
부모 copy하고 pcb만 생성한 자식>> 실제 mem에 x VM으로 있는척
‘지금 쓰는 ‘ page만 올리면 된다.
pgtable의 valid bit : memory에 올라가있다! 의 의미. (disk에도 여전히 원본 존재)
Invlaid: 1) illegal >> 버리면 됨
Not in memory
Obsolete( 최신x) mem의 업데이트된 정보가 disk의 원본 정보와 다름
재빨리 올리는 방법: 메모리에 올린 척만 하고, 올리지 않는다. -> invalid bit
Invalid bit 감지시 page fault exception(fetch시 발생). >> trap 걸고 ‘커널’의 handler로
빈 frame 에 io 시작( 빈 frame x 시 victim page 선정) >> io 완료시
Pgtable 수정. Address를 넣고 Bit 를 Valid 로 변경>> cpu가 언젠가 다시 잡는다.
(실제 HW에선 10bit > 2개 page 1개 pg fault시 둘다 처음부터 다시 해야)
Demand page performance: pg fault 확률 p
(1-p)* mem_access + p*[page fault 오버헤드+swap in+restart overhead
+ ( 만약 변경점 존재시, swap out 으로 업데이트) ]
Or (1-p) * mem_access + p* (page fault service time)
Pg fault: cache 사용하기에 초반에는 cache 채우느라 fault많고,
점점 채워지면 locality로 인해 거의 x >> 한번 disk 접근시 붙어 있는 page 여러 개 가져오자
>>locality로 근처꺼 사용 가능. >> io 횟수 감소
VM 성능에 중요: locality, page 교체 알고리즘
Page 교체
- 누구를 ‘버릴 것인가’
- physical mem과 logical mem의 완전한 분리덕에 가능
- 교체되어 쫒겨날 때, 변경사항을 disk에 write하고 쫒겨나야한다
- modify bit로 교체 오버헤드 감소.
Pg 교체 알고리즘: 전제 상 pg table 개수가 많을수록 mem이 꽉차있을 것이므로
‘Pg table 개수가 클수록 pg fault도 늘어나지 않을까? 라는 개념에서 나왔다.
LRU
최근에 가장 덜 사용된 데이터를 먼저 제거한다.
기본: 가장 나중에 사용된 데이터 -> 부정확하다.
발전: timestamp -> 오버헤드 많다
유사하게 ‘메모리 접근 횟수’ 로 근사 시간을 찾는 방법도 있지만, 여전히 문제가 있다. (search, memacc증가,space 증가
Stack: search x 하지만 linked list 이기에 1개 추가할때마다 io 1번씩 소요되기에 성능 bad!! (io 높음)
LRU approximate
reference bit로 근사치. 페이지 접근시마다 bit를 1로 변경.
Ex: ref 8bit >> 최근 8회 page 접근동안 몇번 쓰였는가.
100 <> 001 왼쪽이더 최근>> ref bit 큰게 더 최근에,자주 쓰인거!
LRU: second chance: 한바퀴 돌면서 바꾸기>> vm1 24p~
LFU: frequency를 기준으로, 가장 낮은 참조 빈도를 가진 데이터를 메모리에서 쫒아낸다.
MFU: 참조 빈도 높은 값을 메모리에서 방출한다. 동영상 재생 스트림 플랫폼에서 좋다.
Frame allocation: 각 process마다 최소한의 page 개수 할당.
Ex: proc1 에 frame 10개 >> 5개 페이지 로 굴림
Local replace: pg fault시 내게 할당된 pg 중 victim 선정
Pg 1개 차이로 엄청난 pg fault 차이가능. (longterm 스케줄러에서 오래걸리는 작업인줄 알고 cpu 더 할당 해주면서 악순환)-> cpu utilization 나빠짐
ex: loop가 4개 frame 사용, 3개 page가 할당됨 >> 4개 pg면 pg fault 가 발생하지 않지만, 1개차이로 loop 도는 만큼 pg fault가 발생한다. ( locality에 맞는 할당 필요!)
따라서 Size of locality가 total allocated memory size가 되도록 적절하게 사이즈를 책정하는 것이 중요하다!
Locality:
Temporal locality: 현재 쓰이는게 곧 다시 쓰일 수도 있다. 라는 생각을 기준으로 locality를 책정한다 ( ex: loop문 등은 계속 반복)
Spatial locality : 참조되는거 주변 메모리 참조 ( array 는 배열 데이터가 메모리의 특정 지역에 밀집하여 저장된다.)
Thrashing: pg fault가 많아, swap (in,out) 이 많아지는 문제 현상을 나타낸다.
working set model
Working set window: 1 2 5 2 3 5…. (page reference table) 에서 고정된 개수
Ex) wsw:3
Working set size: 2 5 2 (임의의 wsw길이만큼) 중 pg 가짓수 >> 2
>> working set에 있는 page들을 계속 mem에 상주시킨다!
각 proc이 필요로하는 모든 frame수 > physical mem 크기 일시 thrashing 발생
. wsm : 매 page ref 마다 갱신> 너무 크다.
Ref bit + interval timer .
Ex: working set window=10k, timer interrupt = 5k
>> 1개 window마다 2번 갱신>> 2개 ref bit ( wsw에 속해있던 주기만 1로)
두 bit 중 1개라도 1이면 wsw에 포함으로 간주.
PFF( pafe fault frequent)
Pg fault가 발생시마다, Pg fault 빈도를 보고 중간으로 조절. (pg fault 높은건
악순환)
VM의 또다른 장점:
- copy on write (COW) 자식, 부모 proc이 page share.
- 만약 특정 부분만 수정시 그부분에 해당하는 page만 copy 생성 후 분리.
- 자식이 exec 되면 그때서야 통째로 분리후 실제 write
가능한 이유: VM은 physical address ‘space’ 와 logical address ‘space’ 가 분리.
Memory mapped file
Proc > ptable 거쳐 실제 mem 접근시, disk file도 바로 읽어올 수 있게
Mem과 disk를 mapped함. -> 이 방식으로 여러 proc이 1개의 file(disk안)
공유할 수 있다. -> file 도 pafe 처럼 share 가능!
*Page size: 너무 커지면 internal fragment 커짐( 작은 놈을 큰곳에)
대신 한번에 많이 읽어올 수 있어 io낮아지고, TLB hit 확률 증가
너무 작아지면 : page table사이즈 증가( 고정된크기에 작아진 pg) ->mem 공간차지
+ 1번에 읽을 수 있는 데이터수가 감소 -> i/o 증가. 단 internal frag 나아짐
TLB reach: TLB크기 * page크기 ( pg size 크면 더 많이 hit)
이상적인 TLB: working set 모두 포함 -> page 크기 다중화!!
i/o interlock: 기껏 disk에서 가져왔는데 버리기 아까움. 핀 꽂아 고정!
File system
data structure in disk
File: contiguous logical address space.
Meta data에 모든 정보 담음 : 파일 데이터 pointer,+ 기타정보들
Directory entry: metadata 의 자료구조. Disk 안에 존재 dir entry를 가진다= 그 dir을 소유함
Open: meta data를 disk> mem으로 load.
Meta data consistency: mem <> disk 의 metadata 일치시켜야
-> 한번에 몰아서 업데이트시 io 감소, cosist 나빠짐
Dir entry 내부: filename+inode ( metadata보유> data 가르키는 포인터 보유)
Metadate search: O(n) 탐색. -> hash로 간소화
디렉터리 구조 > 1단계(root만), 2단계(user당), 트리구조 디렉토리, acyclic(사이클x) 그래프 디렉토리, general graph(사이클 허용 -> 하위 dir이 상위 dir 소유 가능)
Acyclic(사이클x> back edge x) graph 구조: file/dir share가능
Tree와 차이: 같은 file 여러 놈이 가르킬 수 있다. (부모 자식 개념 없다)
하위 file 공유: sumbolic link, hard link 각각문제점
Symbolic link 제거> 남은놈들이 허공 가르키게됨. -> ref bit로 몇 명이 그 파일 가지는지 체크.
Del 명령마다 ref count -- 가 0 되면 실제로 지움.
Hard link: Upade>>consistenct 문제.( 나는 그런거 안했는데?)
General graph directory( 사이클 o)
A > b <> c 에서 a가 b 지우면 c는 접근 불가능하지만, ref count가 여전히 1( b꺼)
쓸모 없는거 못지우는 문제.
Protection: rwx/rwx/rwx >> user, group, owner( 각 file간 관계 다하면너무 많아)
Open: open x 시 a/b/c.file 에서 c.file 접근시마다 c의 meta> b, b의메타> a
이렇게 다 봐야함. open으로 한방에 ok. (disk 안의 file정보 search는 오래걸린다)
Mounting: 각 dir의 root dir을 다른 root의 하위 dir로 붙이기.( div 간 driver 변경할필요x 됨)
Disk에 file date allocation: block단위 (io 비용 크기에 많이씩)
Contiguous alloc
연속적인 블록배정 start, length로 전부 get (시작에서 길이만큼 읽기)
단점: Dynamic alloc이므로 external frag!!!
+ file growth>> internal frag 발생 (여유두고 block 추가할당함)
장점: fast I/O >> 1번의 seek, rotate로 한바퀴 돌면 쭈르륵 읽힘. (head 안움직여도됨)
-> ‘동영상 서버, 멀티미디어 서버, realtime’ 등에 good!!( 한번 실행하면 그대로 쭉)
linked allocation
data 크기 변화에 good!!!!+ block이 여기저기 퍼져도 됨 공간효율 굳
Start, next(포인터) 로 쭉타고감
‘linked list’ >> external, internal fragment 사라진다!!!
단점: random access 불가, 1개 사라지면 연결된 뒤에 다 사라짐, pointer위한 추가 공간,
Disk I/O 효율 bad( 매 sector I/O마다 head 움직이는 seek, rotate)
보완: FAT >> linked list의 포인터를 disk>>mem에 올림 (mem에 올리면 random access 가능해지고, Disk 에게 IO 발생 x) >> 이거 유실되면 큰일이므로 2,3중 copy
Indexed allocation
한블록에 하나의 파일에 대한 데이터 가르키는 포인터 전부 넣기. ( 디렉터리는해당 블록 가르키는 포인터만 저장하면됨)+ random access 가능!!!
>> 하나의 파일이 너무 크면 한블록안에 저장 불가..
Linked 로 붙이기 >> 1개 유실시 다사라짐, but 크기 제한 x 장점.
Two level: indexed block( 1block=1024) >> 1024개의 다른 IB >> 1024*1024개 data block 내장
**Combined: inode안에 data 가르키는 포인터가
Direct block , single indirect(*1024) , double indirect(*1024*1024), triple indirect
1 block= 4kb= 1024*4
Free space management: 빈 block ?? block[i]=0 > 비어있음
Word 단위로 읽으면>> 00100 !=0 이렇게 통으로 가능.
Free block의 block num 계산 : (word의 bit수) *(0의 개수) + offset of first 1 bit.
Ex: 00001 000 >> 앞에 0 4개 >> 4* (word의 bit수)+ 4(첫 1이 4째)
>>> bitmap 순서가 실제 block 순서>> contiguous allocation에 사용가능!!!
Free space mange 방법
-Linked list >>free block 을 link 시킴 >> 장점: 공간 낭비x,
단점: disk I/O로 slow traverse + bitmap 통한 contiguous allocation 이득 x
Grouping: (linked list 보완) block size ==n가정시. N-1에 빈 공간 , 마지막 공간이 다음 블록 포인터( 똑 같은)
Counting: n번 블록부터 m개 연속적으로 있다! > os는 최대한 연속적으로 하려해서 나쁘지 않음.
퍼포먼스 올리기! ( 느린 디스크의)
Disk cache, directory entry cache, virtual disk.
Free behind(다음꺼 불러오고, 최대한 늦게 버림) , read ahead(read시 뒤의 block도 같이 가져오고 cache됨)
>> locality 기반! ( 재사용, 연속 사용)
Disk 에서 최대한 mem에 올린다( random access+ disk I/O 감소) >> consistency문제
Consistency checker : 계속해서 mem의 update를 디스크 반영 + backup
Logical formatting: metadata만 지워서 disk 안 자료구조를 없앰. 실제 data 자체는 disk에 남아있다. ( metadata가 해당 data 가르키는 포인터 보유해
Mass storage
Seek time
head 를 track에 // rotate delay( track에서 원하는 sector 찾는 시간)
하드디스크 위치 정보 : LBA >> HW controller 가 받아서 해석. >> 해당 sector로 (chs)
Os는 LBA만 안다.
Disk bandwidth: 요청~ 완료 까지 시간
Seek time , rotate delay 시간 오래걸림. Seektime은 SW적 개선 가능!
Seektime 은 seek distance 비례 + 최소시간>> seek 수 영향
따라서 seek dist, seek 횟수 줄이자!
LBA번호로 거리 대충 계산( 20번, 21번 간격이 20번 22번 보다 좁을것)
Disk sched
SSTF: SJF 유사.
장점: “seek time 최적화”
단점: starvation, fairness x>> upperbound 없다!!
SCAN, LOOK, C-SCAN, C-LOOK : upperbound 제공!!, starvation x
SCAN: 좌우 이동하며 가는길 전부 탐색
단: 양끝은 1번, 중간은 2번(불균등) , 방향 전환이 무조건 끝부터 끝
C-~ >> 한방향으로만 read, 돌아올때 read x >> 양끝 불균등 해결
~LOOK: data 들어온 곳 까지만 가서 방향전환( 끝까지 x) 가는 중 들어오는 req 반영
공통: arm stickiness 문제
계속 같은 track 번호만 들어오면, 거기 계속 머물러서 starvation 생김( 특수 케이스) RR 같이 쫒아내기 불가.
Physical(low lev) formatting
하드 disk sector 단위로 자름
Sector: (head, trailer, meta data ) >> metadata 검사해 bad sector면 또 bad 가능성
>>bad sector로 이동후 spare sector로 교체 ( hd controller가 하기에 cpu는 이런일 있는지도 모름)
Boot 과정: 메인보드의 rom에 boot strap >> 이거로 sector0 이동 후, 거기서 fullboot strap 으로 부팅.
Disk management
raid ( 낮은 성능의 disk 여러 개를 good 1개처럼 동작하게.
Bit level strip vs block level strip: 읽어들일 단위>> block! ( bit 너무 작아 head 너무 자주 옮김)
단위 작으면 좋은점: ex: bit strip 는 8bit 짜리 정보를 8개 디스크에서 ‘동시에’ seek 가능>
문제
Reliability : 1개만 고장나도 전부 문제>
Redundancy: 여분 데이터 저장해서 해결 >> mirroring(똑 같은 여분 1개)
Mirror: repair 시간 t일시 원본 고장 후 t 시간안에 복사본도 고장나야 에러. Good!
문제: 공간 2배
< 전부 block strip >
Raid 0: redundant x , 신뢰 x 빠름 >> 데이터 상관x 시
Raid 1 : mirror! >> 공간 넘쳐날 때( disk 는 매우 빨리 좋아져서 good)
Raid 4: parity로 신뢰성 챙김 1개 parity block 추가. >>( 0== single 유지되게)
1개 손실시 parity 로 nor하면 원래 값 get .
문제: bottle neck>> parity 제외 n개 block 이 동시 처리하는걸 parity는 혼자>> 젤느려지고,
아무리 동시에 빨리 읽어도 젤 느린 parity block 속도 따라감.(
Raid 5: ( 4 상위호환) parity를 번갈아가며 모든 disk에
Ex: 5 disk 로 묶을 때, n번째 블록 저장하면, n mod 5 +1 째 disk에 parity 블록을 저장, 나머진 data block 저장. >> 부하를 골고루 해서 bottle neck x!
Parity vs mirror
Parity는 공간 절약하지만, 그때 그때 parity 연산 해서 block 만들어야
Mirror: 그냥 복사본에서 뽑아씀..
Lev 1: 공간 충분시
Lev 5: low update rate, 용량 초과할만한 큰 data 있을때.
IO : port, bus, controller
Polling: 무한루프로 주기적으로 될때까지(ready) 확인 (계속 확인해야)
Interrupt: 되면 알려줘 (오버헤드 발생)
Device가 빠르면 polling 이 좋다
Polling: check할 때 ready 만 확인하는게 아님. 주기적으로 라우터에 가서
쌓여있는 네트워크 패킷을 polling으로 싹다 받아옴
로그인 등 중요한거만 interupt로 최대한 빨리.
네트워크 패킷: 빨리, 많이 도착하면 interrupt 오버헤드 너무 늘어남
>> polling으로 쭉 받는다.
Cpu의 interrupt 체크
Fetch> execute> inturpt 체크
Non maskable: interrupt disable로 막을 수 없음( 중요한거)
각 device controller: os 가 보낸 syscall을 각 장치가 알아먹게 변환.
>>일일이 구분하면 너무 많다!
시스템 콜은 두가지로만 분류
Block device: 데이터 저장용. 블록 1개씩 가져오기:read,write,seek (예측가능할 때)
-> memory mapped file access 가능.
Character stream device: 마우스 처럼. 쭉가져오기>> 마우스는 유저가 예측불가한 시간에 누른다. (data size 예측 불가 -> char 방식) : get, put (예측 불가 한거)
Cd Rom: sequential access( disk는 head 움직이며 random access) 따라서 동영상 재생에선 좋을 것.
Blocking: 요청 하고 끝날때까지 자기 일 block 후 대기. (동기화) 되있기에 내 일 끝난거 바로 안다. Easy!
Asychonic: 비동기식
기본>> 시켜놓고 딴일하다 온다 (interupt로 끝난거 알아야함)
Non blocked io >> 던져놓고 대충 (interrupt 없이) 돌아온다. 끝x여도 그거 get
Buffered io
메인 메모리와 디스크 사이에 '버퍼 메모리'를 할당하여 사용한다. 하지만 전원이 나가면 버퍼메모리 속 데이터가 유실 되어 일관성 문제가 생길 수 있다.
Direct io: hard disk에 중간 다리 없이 write 하여 좋은 성능을 기대할 수 있다.
버퍼 장점:
- 속도 차이 완화, ( 빠른놈이 버퍼에다가 써놓고 딴일)
- 데이터 사이즈 변환 ( 블록, 바이트 단위 장치끼리 통신시, 단위 바꾼 뒤 버퍼에 저장)
- Copy semantics : copy는 “copy 요청시” 값을 copy해야함
Disk에 숫자 3 을 proc이 copy 명령, 그리고 되기전에 값이 4로 바뀌어도, 3을 copy해야함.
따라서 copy요청이 control 넘겨주기 전에 “ 커널 스페이스 버퍼(os가 관리함) ”에 copy할 값 넣어놓는다.
Spool: 일은 던져주고 다른일, 할때 던져주는 곳. 직접 요청하는 것이 아닌, Spool 에 던져 놓기만 하면 spool에서 알아서 요청하고 찾아감. ( queue에 쌓아두고 순서대로 요청 후 보내줌)
단점: spool 하는 잠깐 순간에 커널 접근>> 커널 접근 후 해킹 가능
IO 성능 높이기
- Context switch 횟수 감소
- Data copy 감소
- Interrupt 감소 (Pooling, 대량 transfer로 )
- DMA로 ( cpu가 신뢰가능한 mem에게 니가 알아서 뒤처리 하라고 하고 딴일하러)
- Balance cpu, mem, bus, IO 성능 >> bottle neck이 최고의 문제!!( throughput 상승한다)
'운영체제(rebooting now)' 카테고리의 다른 글
| [Operating System] 중간 범위 key note (Process ~ deadlock) (0) | 2023.01.09 |
|---|