스프링 핵심원리 2 [쓰레드 로컬을 통한 동시성 문제해결]
https://codenme.tistory.com/104
스프링 핵심원리-고급편 1 [예제 생성 및 요구사항 이해]
https://www.inflearn.com/course/%EC%8A%A4%ED%94%84%EB%A7%81-%ED%95%B5%EC%8B%AC-%EC%9B%90%EB%A6%AC-%EA%B3%A0%EA%B8%89%ED%8E%B8/dashboard 스프링 핵심 원리 - 고급편 - 인프런 | 강의 스프링의 핵심 원리와 고급 기술들을 깊이있게
codenme.tistory.com
위의 글에서 만든 예제를 develop 하기 위해 쓰레드 로컬 사용에 대해 정리하겠습니다.
우선은, 필드 동기화를 통해 이전의 문제를 해결할 것인데요, 미리 말씀드리면 이 방법은 동시성 문제가 발생하게 됩니다.
따라서 먼저 필드 동기화 방식이 어떻게 동시성 문제를 발생시키는지 알아보고, 쓰레드 로컬을 통해 어떻게 문제를 해결할 수 있는지 알아보겠습니다.
필드 동기화
앞서 로그 추적기를 만들면서 다음 로그를 출력할 때 트랜잭션ID 와 level 을 동기화 하는 문제가 있었다. 이 문제를 해결하기 위해 TraceId 를 파라미터로 넘기도록 구현했다.
이렇게 해서 동기화는 성공했지만, 로그를 출력하는 모든 메서드에 TraceId 파라미터를 추가해야 하는 문제(너무 귀찮고, 가독성도 떨어진다.)가 발생했다.
TraceId 를 파라미터로 넘기지 않고 이 문제를 해결할 수 있는 방법은 없을까?
이런 문제를 해결할 목적으로 새로운 로그 추적기를 만들어보자.
우선 추후에 다양한 구현제로 변경할 수 있도록 LogTrace 인터페이스를 먼저 만들자
public interface LogTrace {
TraceStatus begin(String message);
void end(TraceStatus status);
void exception(TraceStatus status, Exception e);
}
이제 파라미터를 넘기지 않고 TraceId 를 동기화 할 수 있는 FieldLogTrace 구현체를 만들어보자.
이전의 HelloTraceV2와 유사하지만, 변경된 부분만 정리해보겠다.
@Slf4j
public class FieldLogTrace implements LogTrace {
private TraceId traceIdHolder; //traceID를 홀드할 필드를 추가했다.
//traceId 동기화, 동시성 이슈 발생
.........
@Override
public TraceStatus begin(String message) {
//beginsync()로 분리하지 않고, begin()에서 sync로직을 호출하여 동기화를 처리
syncTraceId();
TraceId traceId = traceIdHolder;
Long startTimeMs = System.currentTimeMillis();
log.info("[{}] {}{}", traceId.getId(), addSpace(START_PREFIX, traceId.getLevel()), message);
return new TraceStatus(traceId, startTimeMs, message);
}
private void syncTraceId() { // 동기화 로직 변경- 파라미터로 TraceId를 전달받지 않는다.
if (traceIdHolder == null) {//첫 호출일 경우, 새로 생성
traceIdHolder = new TraceId();
} else {//첫 호출이 아닐 경우, 동기화 수행
traceIdHolder = traceIdHolder.createNextId();
}
}
private void complete(TraceStatus status, Exception e) {
Long stopTimeMs = System.currentTimeMillis();
long resultTimeMs = stopTimeMs - status.getStartTimeMs();
TraceId traceId = status.getTraceId();
if (e == null) {
log.info("[{}] {}{} time={}ms", traceId.getId(), addSpace(COMPLETE_PREFIX, traceId.getLevel()), status.getMessage(), resultTimeMs);
} else {
log.info("[{}] {}{} time={}ms ex={}", traceId.getId(), addSpace(EX_PREFIX, traceId.getLevel()), status.getMessage(), resultTimeMs, e.toString());
}
releaseTraceId();//releaseTraceId() 메소드 호출 추가
}
private void releaseTraceId() { // 신규 메소드
if (traceIdHolder.isFirstLevel()) {
traceIdHolder = null; //destroy
} else {
traceIdHolder = traceIdHolder.createPreviousId();
}
}
}TraceId 를 동기화 하는 부분만 파라미터를 사용하는 것에서 TraceId traceIdHolder 필드를 사용하도록 변경되었다.
중요한 부분은 로그를 시작할 때 호출하는 syncTraceId() 와 로그를 종료할 때 호출하는 releaseTraceId() 이다.
syncTraceId()
- TraceId 를 새로 만들거나 앞선 로그의 TraceId 를 참고해서 동기화하고, level 도 증가한다.
- 최초 호출이면 TraceId 를 새로 만든다.
- 직전 로그가 있으면 해당 로그의 TraceId 를 참고해서 동기화하고, level 도 하나 증가한다.
- 결과를 traceIdHolder 에 보관한다.
releaseTraceId()
- 메서드를 추가로 호출할 때는 level 이 하나 증가해야 하지만, 메서드 호출이 끝나면 level 이 하나
감소해야 한다.
- releaseTraceId() 는 level 을 하나 감소한다.
- 만약 최초 호출( level==0 )이면 내부에서 관리하는 traceId 를 제거한다.
이제 Controller-Service-Repository의 메소드에서, 시작할 때 begin()을 최초 호출 여부와 관계 없이 호출하고,
파라미터도 전달하지 않고 수행하도록 변경하고, 각각의 메소드에서 정상 종료시 end()메소드를, 예외 발생 시
exceptioin() 메소드를 호출하도록 변경하면 된다.
하지만 FieldLogTrace 는 심각한 동시성 문제를 가지고 있다.
동시성 문제를 확인하려면 다음과 같이 동시에 여러번 호출해보면 된다(같은 로직을 동시에 여러번 실행).
기대한 결과(흐름대로)
동시에 여러 사용자가 요청하면 여러 쓰레드가 동시에 애플리케이션 로직을 호출하게 된다. 따라서 로그는 이렇게 섞여서 출력된다.

기대하는 결과 (로그 분리해서 확인하기)
로그가 섞여서 출력되더라도 특정 트랜잭션ID로 구분해서 직접 분류해보면 아래와 같이 깔끔하게 분리하고 싶다.

그런데 실제 결과는 기대한 것과 다르게 다음과 같이 출력된다.
실제 결과(흐름대로)

실제 결과 (로그 분리해서 확인하기)


기대한것과전혀다른문제가발생한다. 트랜잭션ID도 [aaaaaaaa]로 동일하고,level도 꼬여있다(exec-4의 컨트롤러는 level 0부터 시작해야하지만, level 3부터 시작한다.) 즉, exec-3의 연장선으로 들어가버린 것이다.
동시성 문제
FieldLogTrace 는 싱글톤으로 등록된 스프링 빈이다. 이 객체의 인스턴스가 애플리케이션에 딱 1 존재한다는 뜻이다. 이렇게 하나만 있는 인스턴스의 FieldLogTrace.traceIdHolder 필드를 여러 쓰레드가 동시에 접근하기 때문에 문제가 발생한다.
따라서, 만약 exec-3이 아직 trace.end()로 종료하지 않았는데, exec-4가 실행된다면, 싱글톤으로 공유하는 하나의 인스턴스
FieldLogTrace를 공유하게 되고, 기존의 exec-3이 Repository영역을 수행중이라 traceIdHolder 필드가 여전히 level 3인채로
exec-4의 Controller가 시작되고, 이 값을 물고오는 것이다.
스프링 빈 처럼 싱글톤 객체의 필드를 변경하며 사용할 때에는, 이러한 동시성 문제를 조심해야 한다.
**참고
이런 동시성 문제는 지역 변수에서는 발생하지 않는다. 지역 변수는 쓰레드마다 각각 다른 메모리 영역이
할당된다.
동시성 문제가 발생하는 곳은 같은 인스턴스의 필드(주로 싱글톤에서 자주 발생), 또는 static 같은 공용
필드에 접근할 때 발생한다.(서로 다른 스레드도 같은 메모리 영역을 공유한다, 이는 쓰레드가 공용자원을 사용하여
메모리 영역을 절약하는 장점으로도 동작하지만, 동시성 문제라는 양날의 검으로도 동작할 수 있다.)
또한 동시성 문제는 값을 읽기만 하면 발생하지 않는다. 어디선가 값을 변경하기 때문에 발생한다.
ex) Read <> Read는 동시에 접근해도, 같은 결과가 나오기에 상관 없다.
하지만, Write 발생 후 read 같은 경우는, 기존의 read할 값이 아닌, Write가 수행된 값을 read하므로, 의도와 다른 read를 수행하는 치명적 문제가 생긴다.
그렇다면 지금처럼 싱글톤 객체의 필드를 사용하면서 동시성 문제를 해결하려면 어떻게 해야할까? 다시 파라미터를 전달하는 방식으로 돌아가야 할까? 이럴 때 사용하는 것이 바로 쓰레드 로컬이다.
ThreadLocal
쓰레드 로컬은 해당 쓰레드만 접근할 수 있는 특별한 저장소를 말한다.

thread-A 가 userA 라는 값을 저장하고
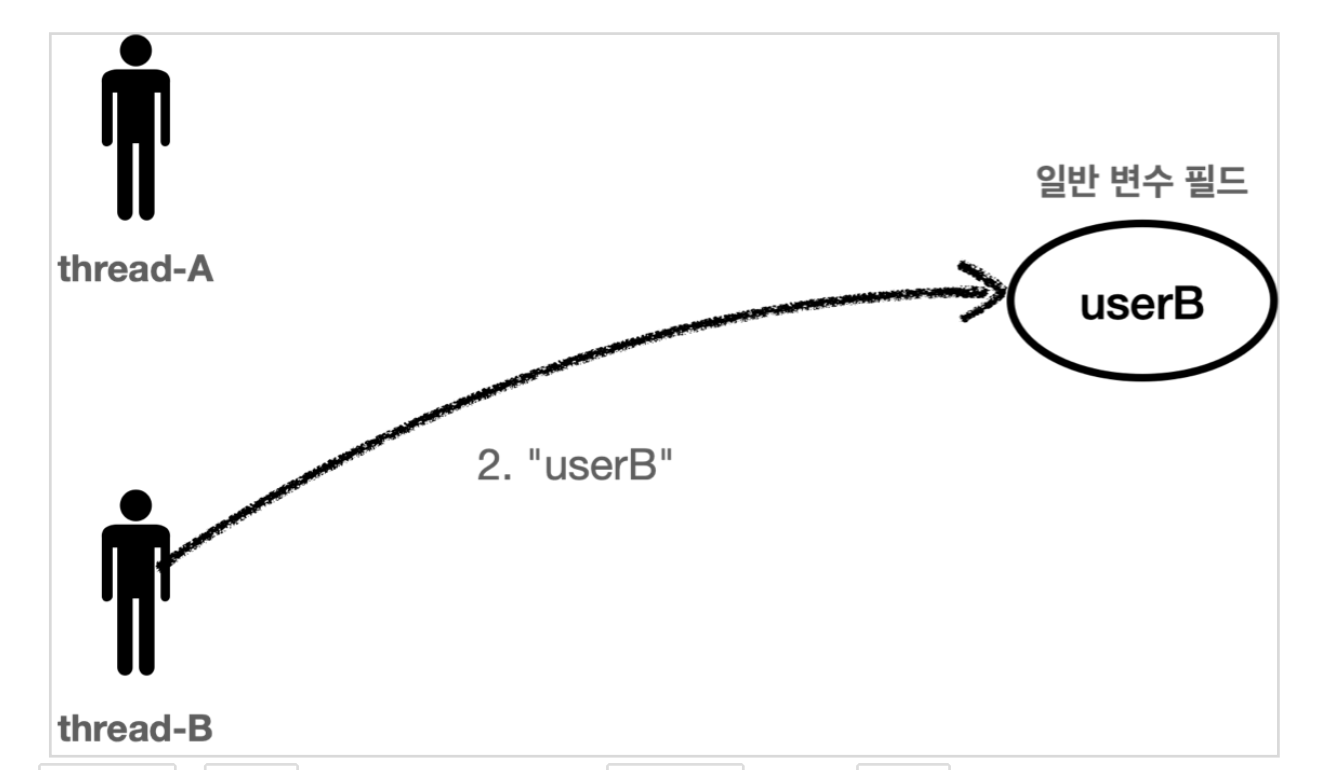
thread-B 가 userB 라는 값을 저장하면 직전에 thread-A 가 저장한 userA 값은 사라진다.
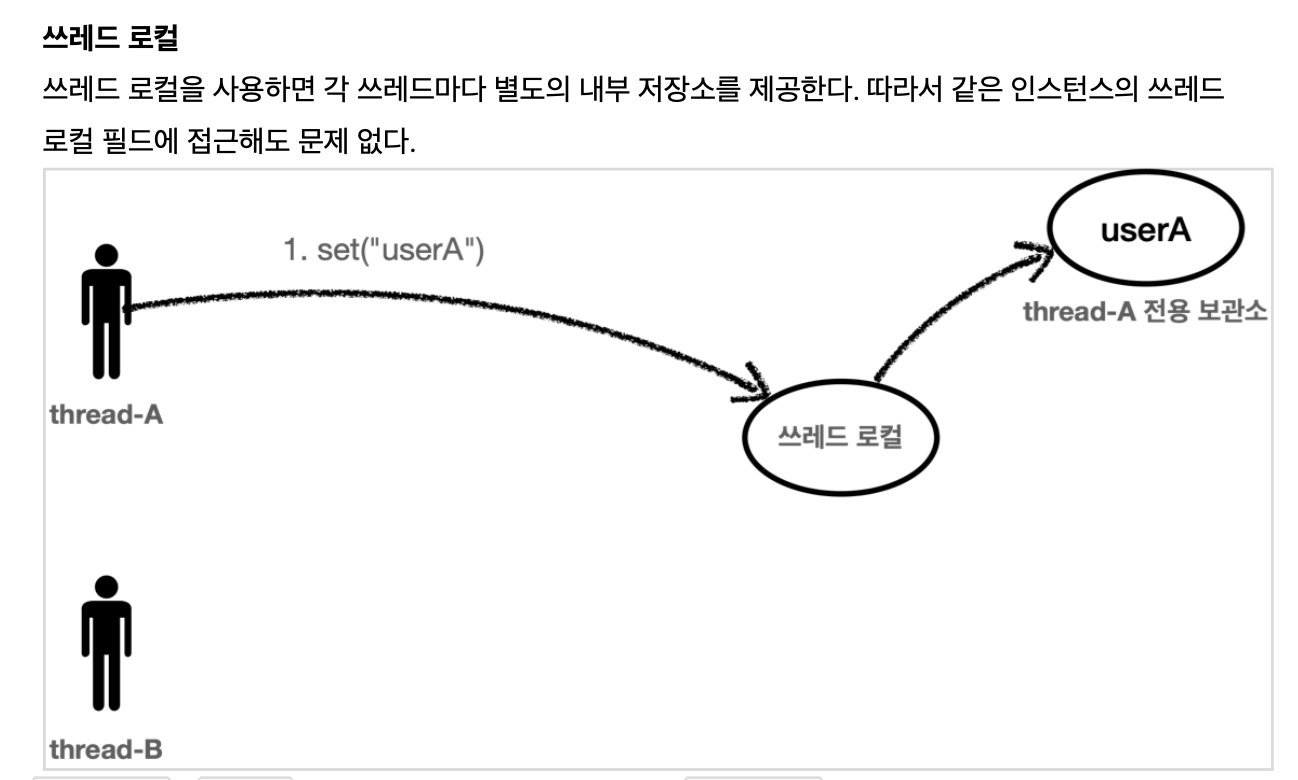
thread-A 가 userA 라는 값을 저장하면 쓰레드 로컬은 thread-A 전용 보관소에 데이터를 안전하게 보관한다.
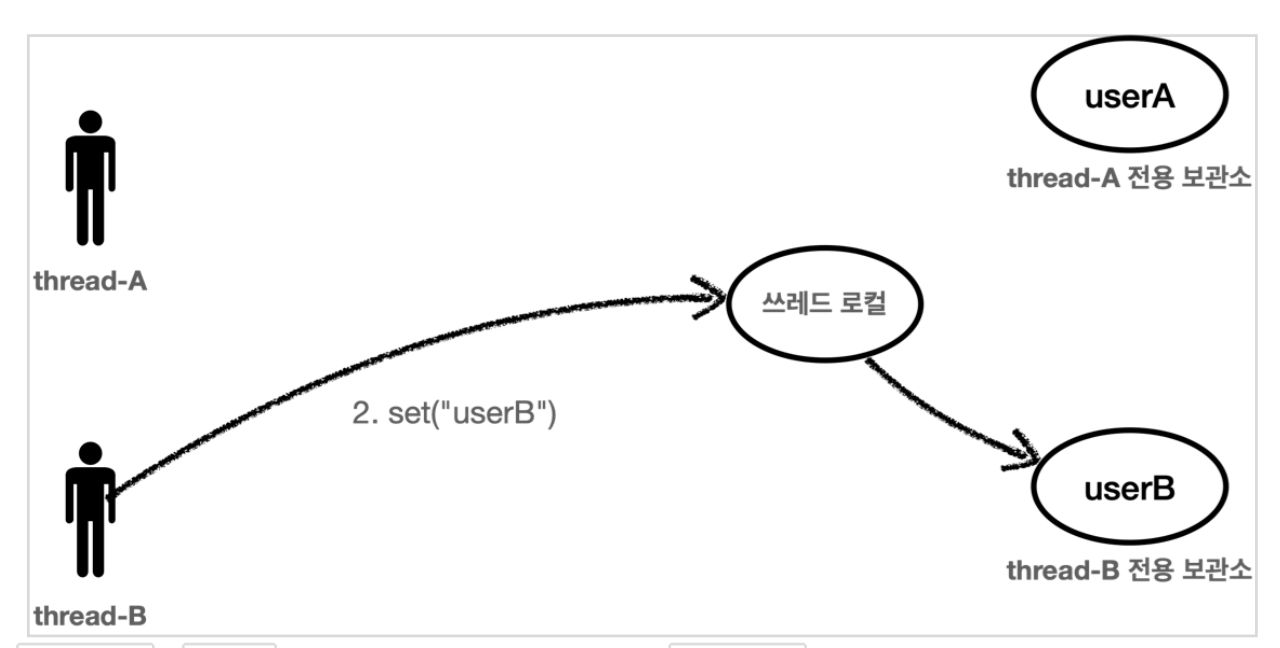
thread-B 가 userB 라는 값을 저장하면 쓰레드 로컬은 thread-B 전용 보관소에 데이터를 안전하게 보관한다.
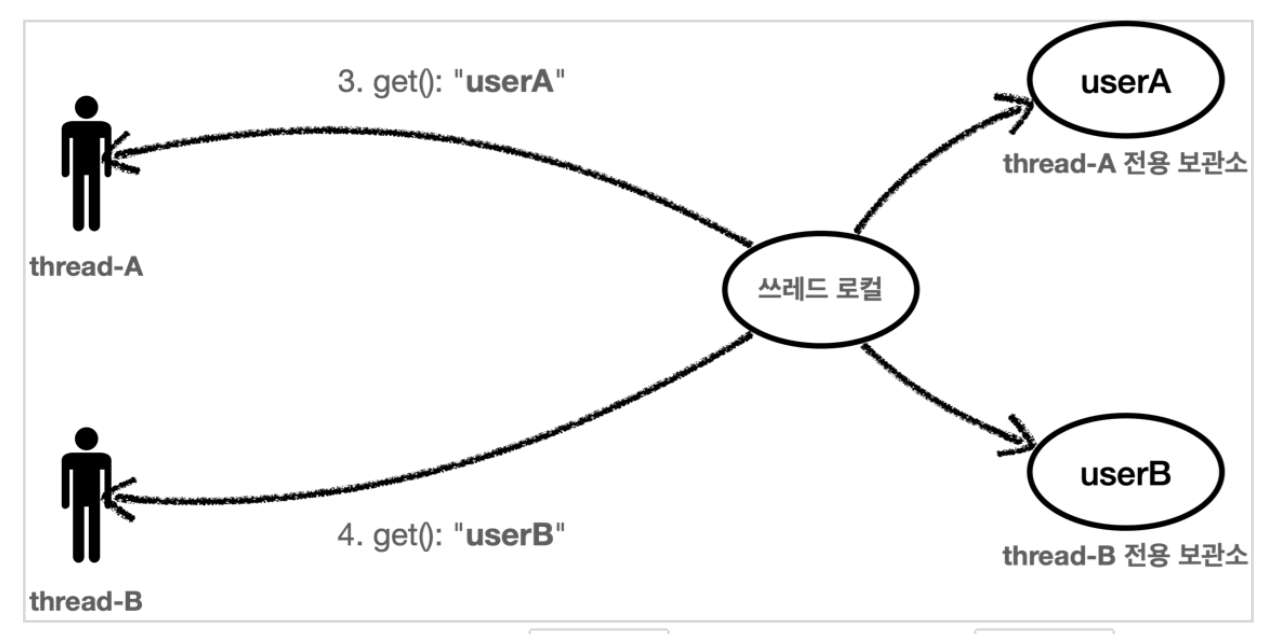
쓰레드 로컬을 통해서 데이터를 조회할 때도 thread-A 가 조회하면 쓰레드 로컬은 thread-A 전용 보관소에서 userA 데이터를 반환해준다. 물론 thread-B 가 조회하면 thread-B 전용 보관소에서 userB 데이터를 반환해준다.
자바는 언어차원에서 쓰레드 로컬을 지원하기 위한 java.lang.ThreadLocal 클래스를 제공한다.
즉, 이러한 ThreadLocal을 사용하면, 완벽한 동시 요청이 들어오더라도, 쓰레드 별로 구분된 저장소에서 값을 가져오기에, 문제가 전혀 발생하지 않는다.( log 추적기가, 여러 요청이 동시 수행되더라도 각각의 요청(스레드) 전용 보관소에서 가져오기에, 동시성 문제가 해결된다.)
쓰레드 로컬 사용 예시
@Slf4j
public class ThreadLocalService {
private ThreadLocal<String> nameStore = new ThreadLocal<>(); //쓰레드 로컬 사용!
public String logic(String name) {
log.info("저장 name={} -> nameStore={}", name, nameStore.get());
nameStore.set(name); //쓰레드 로컬에서 사용
sleep(1000);
log.info("조회 nameStore={}", nameStore.get());
return nameStore.get();
}
private void sleep(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
아래와 같이 쓰레드 로컬을 사용하면, 이제 요청별(쓰레드별) 독립적인 저장소인 쓰레드 로컬에 name값을 유지 시킬 수 있다.
private ThreadLocal<String> nameStore = new ThreadLocal<>();
이렇게 하면,
테스트
@Slf4j
public class ThreadLocalServiceTest {
private ThreadLocalService service = new ThreadLocalService();
@Test
void field() {
Thread threadA = new Thread(userA);
threadA.setName("thread-A");
//// sleep(2000); //동시성 문제 발생X 위한 sleep
Thread threadB = new Thread(userB);
threadB.setName("thread-B");
log.info("threadA Name={}",threadA.getName());
log.info("threadA Name={}",threadB.getName());
}
}결과

동시 요청이 수행되어도, 올바르게 각각의 스레드 저장소에서 값을 가져온다.
ThreadLocal 사용법
- 값 저장: ThreadLocal.set(xxx)
- 값 조회: ThreadLocal.get(
- 값 제거: ThreadLocal.remove()
**주의
해당 쓰레드가 쓰레드 로컬을 모두 사용하고 나면 ThreadLocal.remove() 를 호출해서 쓰레드 로컬에
저장된 값을 제거해주어야 한다.
쓰레드 로컬 동기화 - 개발
이제 FieldLogTrace 에서 발생했던 동시성 문제를 ThreadLocal 로 해결해보자.
TraceId traceIdHolder 필드를 쓰레드 로컬을 사용하도록 ThreadLocal<TraceId> traceIdHolder 로 변경하면 된다.
필드 대신에 쓰레드 로컬을 사용해서 데이터를 동기화하는 ThreadLocalLogTrace 를 새로 만들자.
@Slf4j
public class ThreadLocalLogTrace implements LogTrace {
.......
private ThreadLocal<TraceId> traceIdHolder = new ThreadLocal<>();
// private TraceId traceIdHolder; 이제 쓰레드 로컬로 변경했다!
.........
private void syncTraceId() {
TraceId traceId = traceIdHolder.get(); //.get()으로 쓰레드 로컬에서 값 가져오기
if (traceId == null) {
traceIdHolder.set(new TraceId()); //.set으로 쓰레드 로컬에 값을 할당
} else {
traceIdHolder.set(traceId.createNextId()); //.set으로 쓰레드 로컬에 값을 할당
}
}
private void releaseTraceId() {
TraceId traceId = traceIdHolder.get();
if (traceId.isFirstLevel()) {
traceIdHolder.remove(); //첫 요청 시, 기존의 쓰레드 로컬 저장소 초기화!
} else {
traceIdHolder.set(traceId.createPreviousId());
}
}
.......
}traceIdHolder 가 필드에서 ThreadLocal 로 변경되었다.
따라서 값을 저장할 때는 set(..) 을 사용하고, 값을 조회할 때는 get() 을 사용한다.
이제, syncTraceId() 를 통해 level이 0 -> 1 -> 2 .. 처럼 점점 높아지고,
releaseTraceId()를 사용 시 level이 2-> 1 ->0 처럼 점점 줄어든다.
결과적으로 만약 메소드를 통해 Controller(lev 0) -> Service (lev 1) -> Repository (lev2) 로 호출되면
lev 0 시작 -> lev 1 시작 -> lev 2 시작 -> lev 2 종료 -> lev 1 종료 -> lev 0 종료 와 같이 메소드 호출, 종료가
올바르게 표현될 수 있다.
이제 위의 ThreadLocalLogTrace를 인터페이스의 구현체로 변경하고 테스트 해보자.
@Configuration
public class LogTraceConfig {
@Bean
public LogTrace logTrace() {
//return new FieldLogTrace();
return new ThreadLocalLogTrace();//새로운 구현체로 변경!
}
}
실행 결과(흐름대로)

실행 결과(로그 분리해서 확인하기)

더이상 동시 요청을 해도, 다른 쓰레드의 traceHolder를 가져오지 않도록 ThreadLocal에 Traceid를 저장했기에,
동시 요청이 수행되도, 올바르게 TradeId의 transacionId (4568423c 등) 가 같거나, level이 이전 요청과 섞이는 등의 문제가 생기지 않는다.
쓰레드 로컬 - 주의사항
쓰레드 로컬의 값을 사용 후 제거하지 않고 그냥 두면 WAS(톰캣)처럼 쓰레드 풀을 사용하는 경우에 심각한 문제가 발생할 수 있다.
다음 예시를 통해서 알아보자.
was는 쓰레드 풀을 통해, 쓰레드를 요청마다 그때 그때 생성하고 제거하는 것이 아니라, 매 요청마다 쓰레드 풀에 있는 쓰레드를 가져와서 사용하는 것이다. 따라서, 만약 쓰레드 로컬을 비우지 않는다면, 쓰레드 풀에 여전히 값이 남아있고, 전혀 상관 없는 요청이 해당 쓰레드를
쓰레드 풀로부터 받아서 사용하더라도, 저장소에 이 값이 여전히 남아있게 되는 것이다.
사용자 A 저장 요청
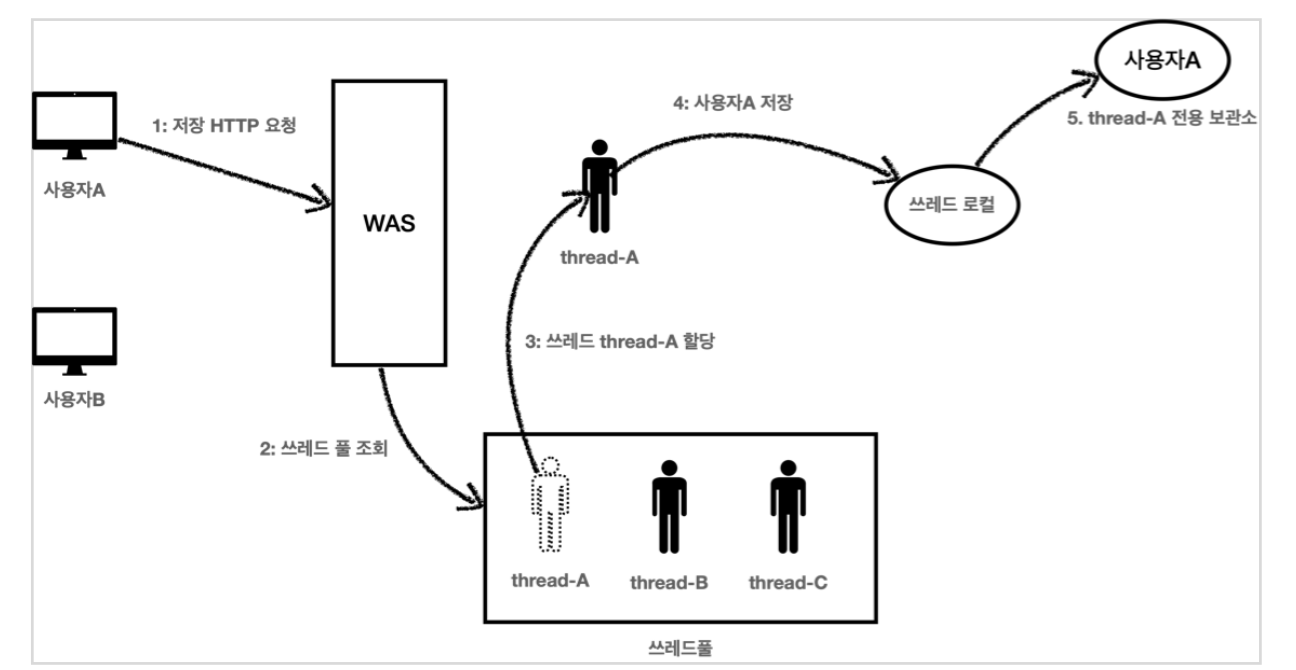
1. 사용자A가 저장 HTTP를 요청했다.
2. WAS는 쓰레드 풀에서 쓰레드를 하나 조회한다.
3. 쓰레드 thread-A 가 할당되었다.
4. thread-A 는 사용자A 의 데이터를 쓰레드 로컬에 저장한다.
5. 쓰레드 로컬의 thread-A 전용 보관소에 사용자A 데이터를 보관한다.
사용자 A 저장 요청 종료
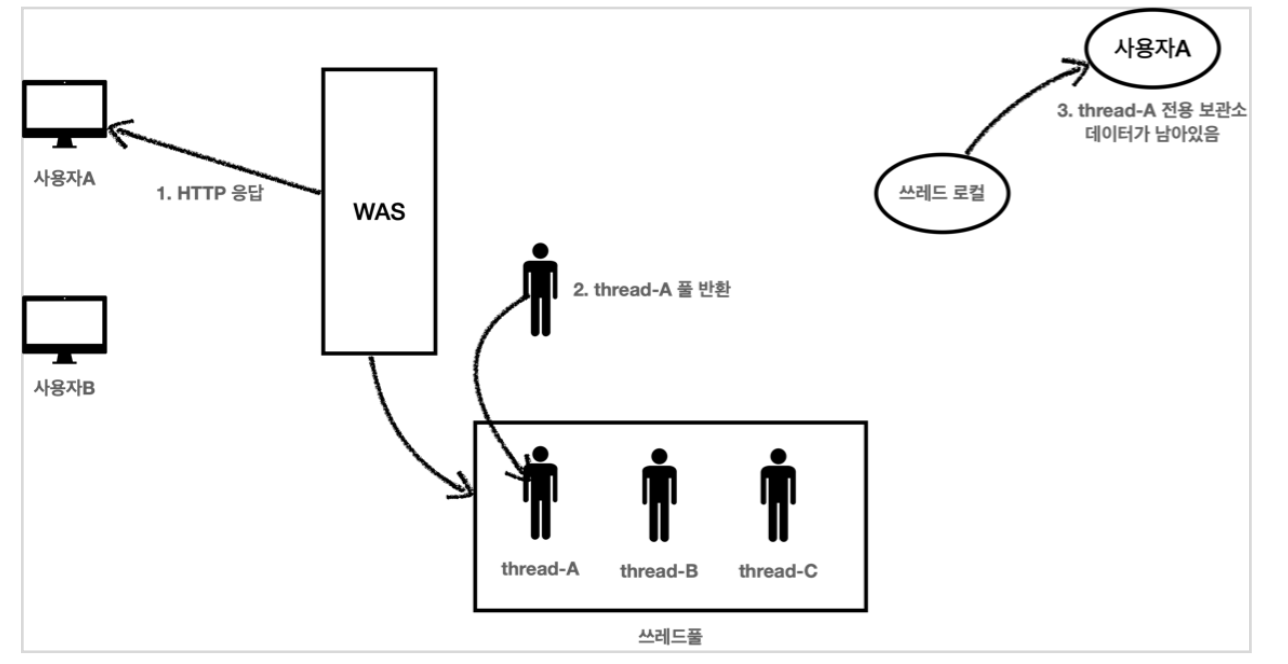
1. 사용자A의 HTTP 응답이 끝난다.
2. WAS는 사용이 끝난 thread-A 를 쓰레드 풀에 반환한다. 쓰레드를 생성하는 비용은 비싸기 때문에 쓰레드를 제거하지 않고, 보통 쓰레드 풀을 통해서 쓰레드를 재사용한다.
3. thread-A 는 쓰레드풀에 아직 살아있다. 따라서 쓰레드 로컬의 thread-A 전용 보관소에 사용자A 데이터도 함께 살아있게 된다.
사용자 B 조회 요청
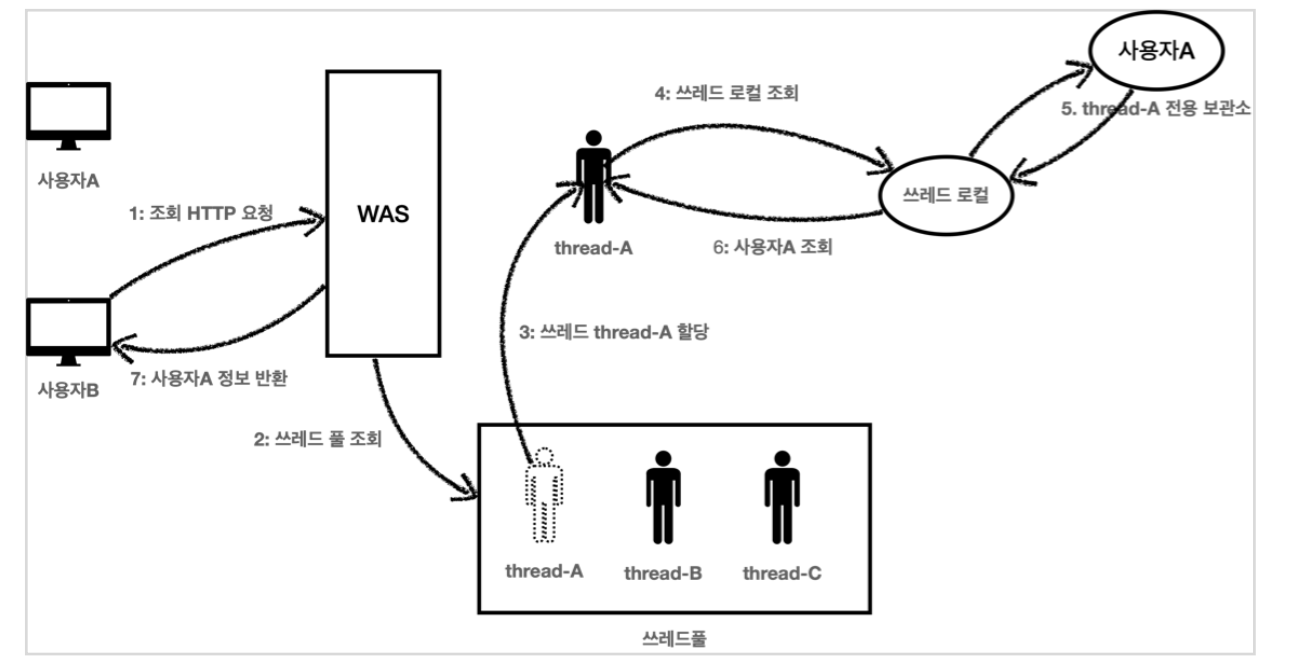
1. 사용자B가 조회를 위한 새로운 HTTP 요청을 한다.
2. WAS는 쓰레드 풀에서 쓰레드를 하나 조회한다.
3. 쓰레드 thread-A 가 할당되었다. (물론 다른 쓰레드가 할당될 수 도 있다.)
4. 이번에는 조회하는 요청이다. thread-A 는 쓰레드 로컬에서 데이터를 조회한다. 5. 쓰레드 로컬은 thread-A 전용 보관소에 있는 사용자A 값을 반환한다.
6. 결과적으로 사용자A 값이 반환된다.
7. 사용자B는 사용자A의 정보를 조회하게 된다.
따라서, 쓰레드 로컬의 값을 ThreadLocal.remove() 를 통해서 꼭 제거해야 한다.
정리
- 파라미터 전달 방식을 통한 동기화는 메소드마다 파라미터를 전달해야해서 코드가 지저분해지고 유지보수가 어려워진다.
- 공통 필드를 사용 시, 각 요청마다 쓰레드가 생겨 사용하지만, 쓰레드는 공통 필드에 대해 공용 메모리 공간을 가지기에,
여러 쓰레드가 동시접근 시, 문제가 생긴다
-쓰레드 로컬은 쓰레드마다 개별적 저장소를 가지기에, 이를 사용하면, 동시성 문제를 해결할 수 있다.